

Practical Secure Aggregation for Privacy-Preserving Machine Learning
文章由谷歌大佬们于2017年发表在密码学领域顶会CCS上,我曾试图寻找这个聚合协议的漏洞/缺陷,但最后得出的结论是:实在是太精妙了
1.背景
机器学习模型通常会包含大量的神经网络参数,而在联邦学习的场景中,用户在本地训练好模型后,需要将这些参数上传至服务器进行聚合,但直接上传是存在隐私泄露的风险的,因此需要将所有参数进行加密再进行聚合。
我们知道加密解密的运算时间是不容忽视的,特别是在训练深度学习神经网络时,模型参数可能达到上千个甚至上万个,对这些模型参数加密并满足同态的性质是一个极具挑战的任务。
2.贡献
(1)支持高维向量的加密
(2)即使每一轮有新的用户加入,该方案也能保持高效的通信
(3)能够应付用户掉线的情况
(4)在以服务器为中介的、未经身份验证的网络模型的约束下提供最强的安全性
3.预备知识
3.1 Key Agreement

核心即Diffie-Hellman密钥交换,两个用户可以协商一个共享密钥
3.2 Secret Sharing

核心为shamir的(t, n)秘密分享方案,将要分享的秘密参数s通过多项式分成n份,只有满足至少t份份额才可解密得到s
3.3 加密、哈希、签名

其中的PRG为伪随机生成器,通过一个种子可以生成一个无限的伪随机输出序列,加密和签名为密码学基本工具,在此不再赘述
4.协议构造
该方案假设用户id有序,且以下算法是以单次聚合的角度进行讨论,但我们知道机器学习需要多次聚合才能收敛到阈值,因此以下讨论的步骤需要在每一次聚合时执行。
4.1 加密构思
我们首先关注一下如何解决加密的问题,文章中提到,开始的设计方案如下所示:
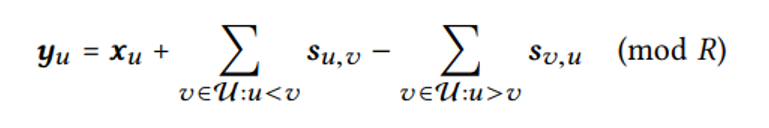
其中,s_{u,v}为用户u通过与每一个其他用户进行KA(s_u^{SK}, s_v^{PK})(Key Agreement)得到,若当前用户u的id大于v的id则加密时相加,否则相减。直观的可以得到,当所有用户上传参数后,这些加密的参数自然而然能够抵消。
然而,这种方法显然存在问题,首先就是巨大的计算和通信开销,为了保证加密参数的随机性,这种方法需要对每个模型参数都进行一次KA协商,那么通信代价为O(N*d),其中N为用户总数,d为向量维度(模型参数总数),那么论文中对加密方式进行了改造,如下所示:
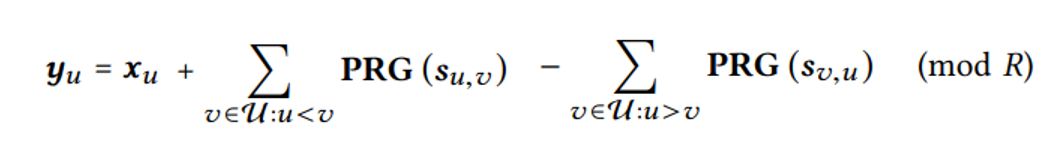
其中,PRG代表伪随机数生成器,这个式子含义为当所有用户都使用同一个种子,就能实现每一对用户都只需要协商一次KA,通过该种子生成与模型参数等同维度的随机数并相加,如此便能实现加密式子的随机性,便能实现O(N)的通信代价。
那么,如何解决掉线问题,文章使用了shamir大神的秘密共享方案,用户u将自己的私钥s_{u}^{SK}作为秘密共享参数,把不同的份额分发给其他用户,在聚合阶段若用户u掉线,那么通过其他至少t个用户便能恢复出密钥。
看似已经解决了所有问题,但是考虑这种情况,若用户u很晚才将参数上传,但此时服务器判定用户u已经掉线并让其他用户恢复了该用户的私钥,那么此时便能破解用户u的参数。考虑更坏的情况,好奇的服务器可以撒谎用户u掉线,这样一来,方案还无法构成足够的安全。
因此文章提出了最终的方案,如下所示:
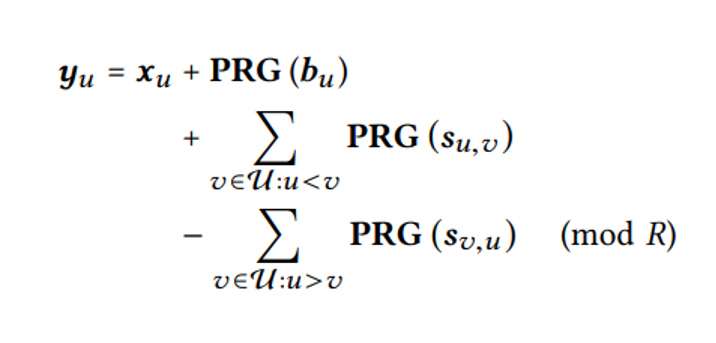
其中b_u为用户u自行添加的秘密参数,和s_u一样需要将不同的份额分发给其他用户,但是区别就在于b_u是若用户u在线才恢复,而s_u是用户u掉线时恢复,如此一来,一个诚实的用户v便不会同时提交用户u的两个秘密份额。
4.2 方案具体流程
我们以用户u作为视角作为讨论,其余的用户执行的操作与用户u相同。
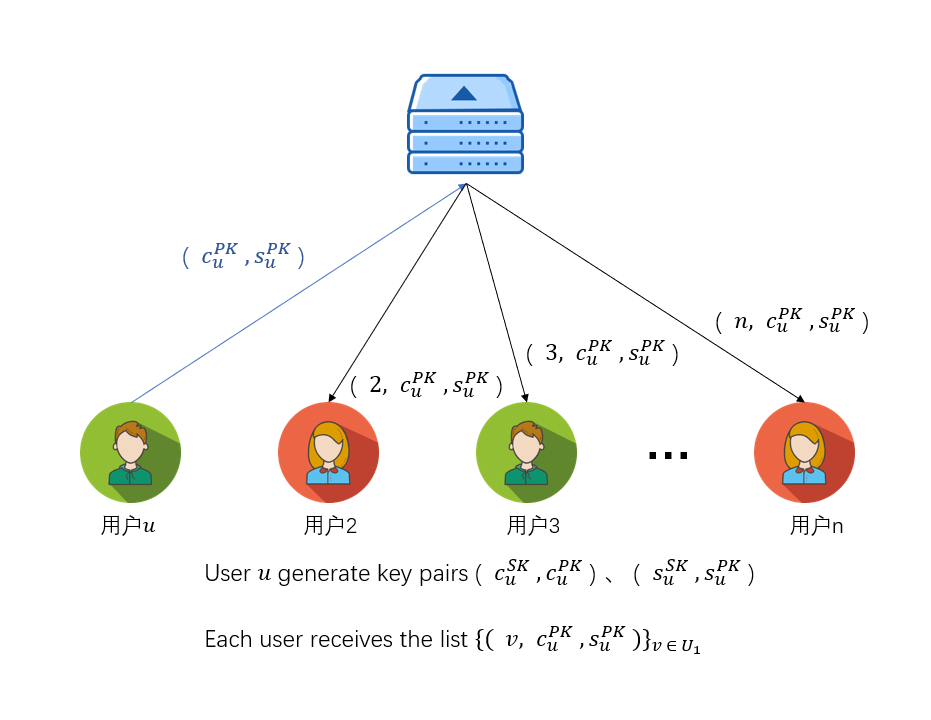
Round 0
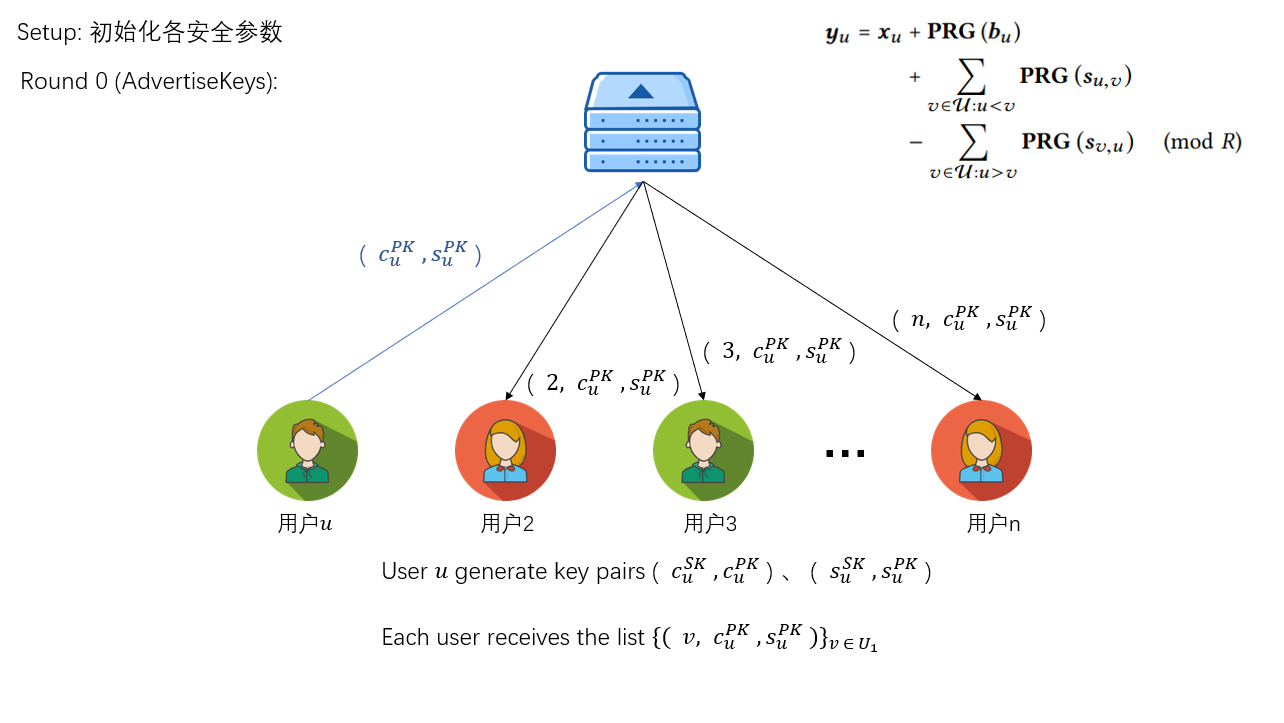
首先初始化各安全参数,接着第一步便是将公钥(c_{u}^{PK}, s_{u}^{PK})发送给服务器,服务器路由给其他用户,其他用户拿到用户u的公钥后与自己的私钥(c_{v}^{SK}, s_{v}^{SK})结合便能得到两个共享密钥,值得一提的是c_{u,v}用来后续加密传输的信息,而s_{u,v}用来加密模型参数。
Round 1
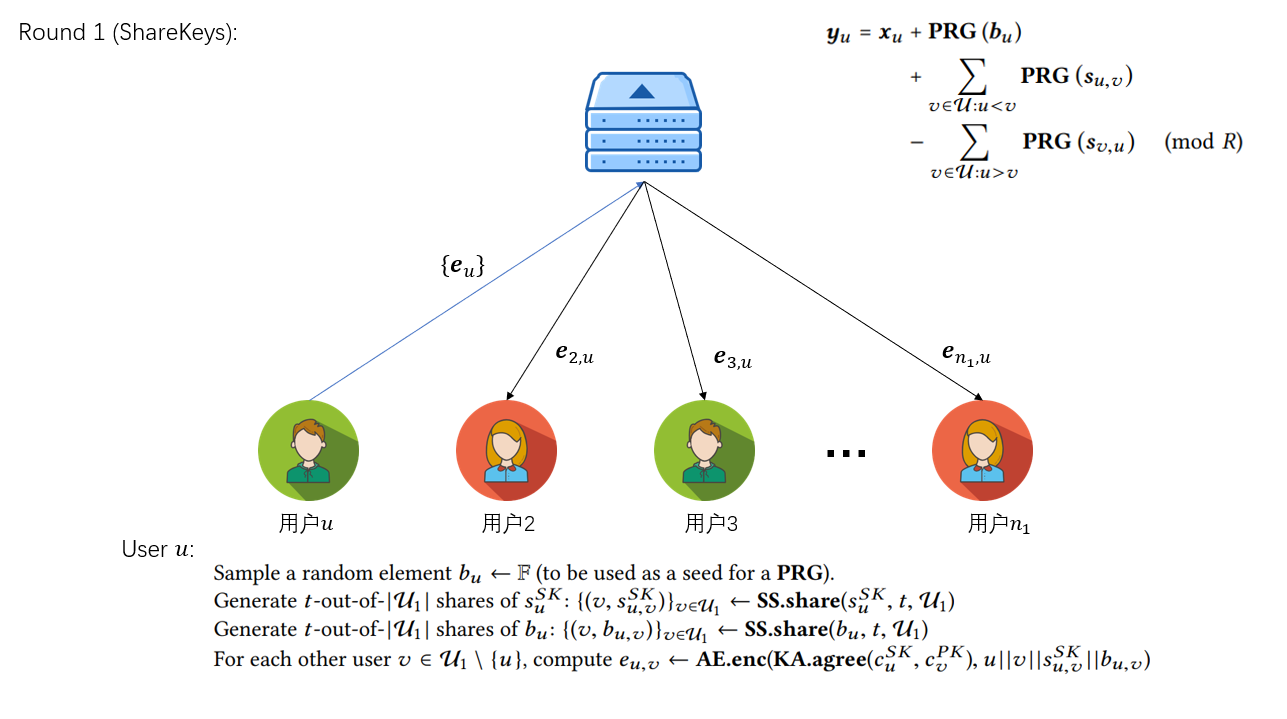
将b_u与s_u的秘密份额通过Round 0得到的c_{u,v}加密发送给对应的其他用户
Round 2
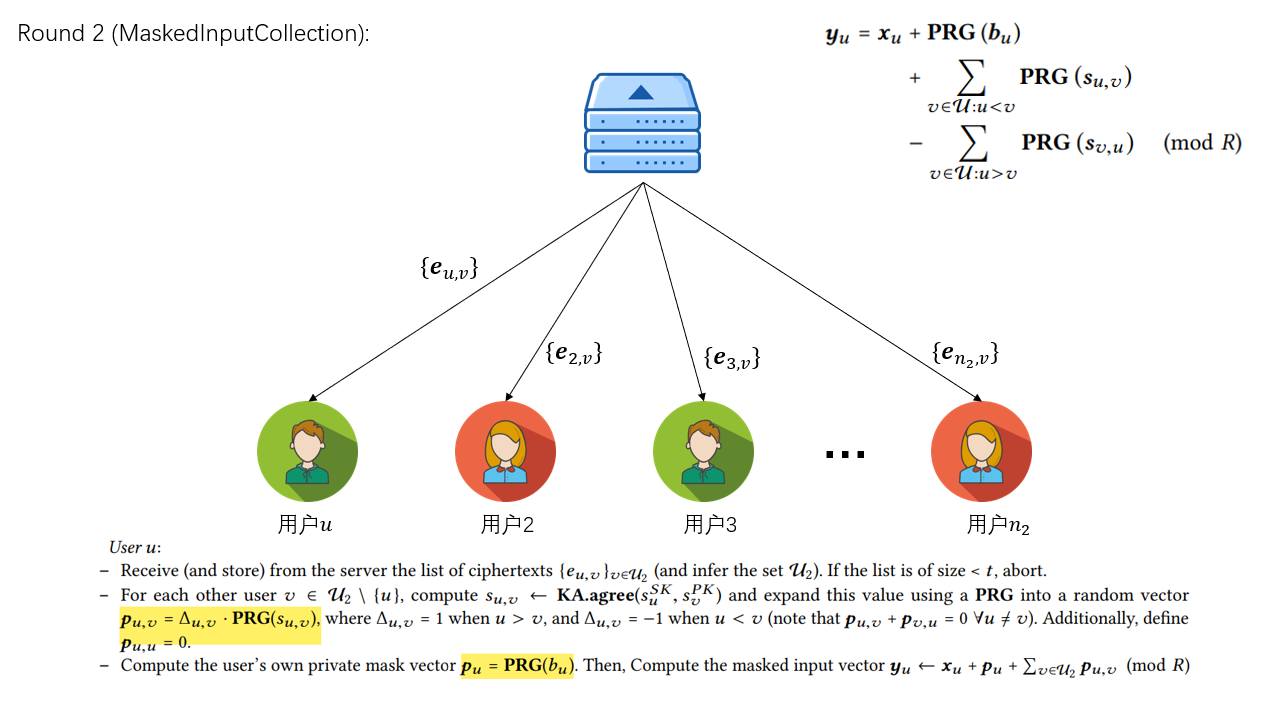
从服务端收到其他用户发送给自己的秘密份额后,根据收到的用户列表,计算PRG(s_{u,v})和PRG(b_{u}),注意这是每个参数都需要哈希一次,保证每个位置上的参数加密的数都是随机的。计算完成后将加密后的参数上传给服务器。
Round 3
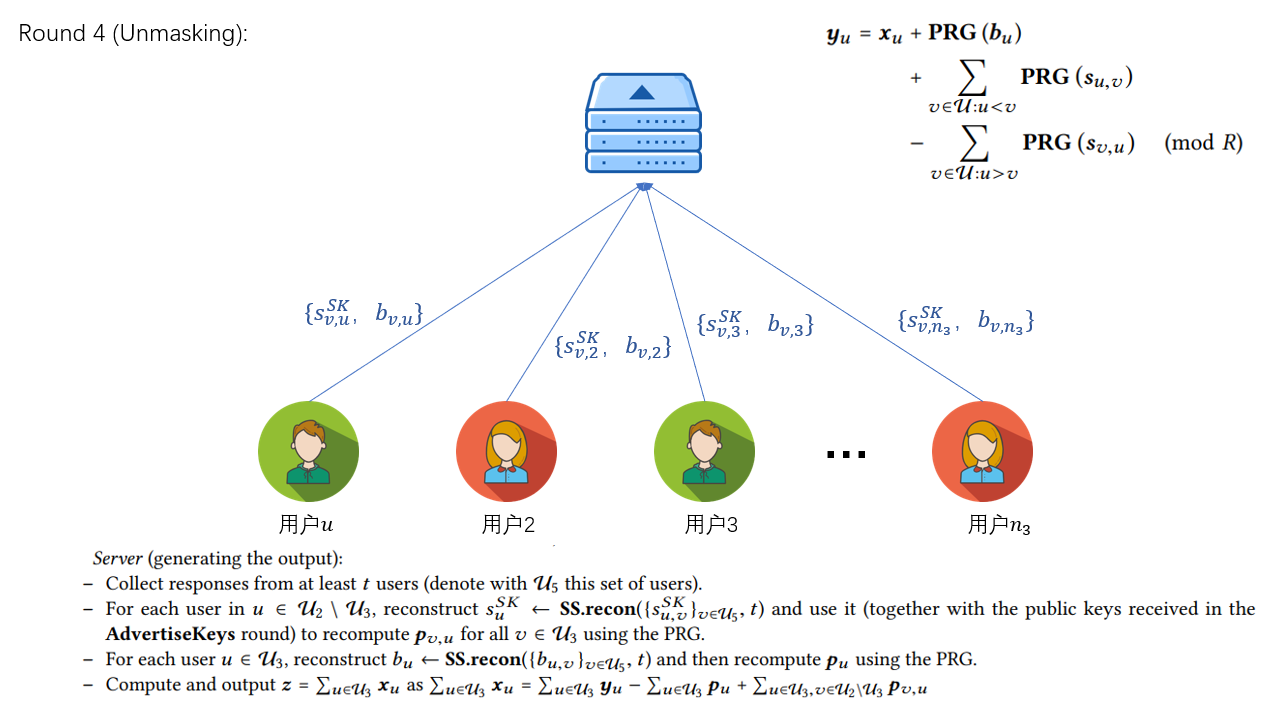
服务器将收到的模型参数进行聚合并将掉线用户列表发送给所有用户,用户通过该列表上传掉线用户的秘密份额s_{j}^{'}和在线用户的秘密份额b_{i}^{'},服务器收到至少t个用户上传的份额后恢复对应参数,得到聚合结果。
4.3 一些细节
从上述的方案我们可以得知,服务器主要做的路由的作用,完成用户之间信息的交换,因此服务器有能力对不同的用户宣称不同的用户掉线,借此来试图破解shamir秘密共享中的多项式,因此原论文还加了一轮一致性检测,感兴趣的朋友可以去原论文看看~
附:
注:以上方案流程图中的图标来自阿里icon,侵删
原文链接:Practical Secure Aggregation for Privacy-Preserving Machine Learning
shamir秘密分享:How to share secret




Hi, i think that i saw you visited my weblog so i
came to “return the favor”.I am attempting to find things to improve my
web site!I suppose its ok to use a few of your
ideas!!
“PRG就代表哈希,这个式子含义为当所有用户都使用同一个哈希函数并遵循一定的规则,就能实现每一对用户都只需要协商一次KA,并将该值哈希d次实现加密式子的随机性,便能实现O(N)的通信代价。” 我认为KA的协商应该不是一次多用,若多用在用户多次掉线后,用户的梯度很可能会变得不安全。
勘误:最近发现PRG严格来说应该是伪随机数生成器,跟哈希还是有点区别,PRG可以通过一个种子生成无限的伪随机序列,并且通过同样的种子伪随机序列是确定的。在这篇论文中,每一轮全局模型训练都会重新更新密钥信息,因此每一轮的梯度都是由不同的种子生成的随机数。考虑到用户掉线的问题,在恢复密钥的时候是结合了恢复在线用户的秘密参数b,和掉线用户的秘密参数s,因此在论文的安全设定下是安全的。
After exploring a number of the articles on your website, I
seriously appreciate your technique of blogging.
I bookmarked it to my bookmark webpage list and will be checking back in the near future.
Please visit my website too and tell me what you think.